

Écrit par

Vous vous sentez perdu face aux termes techniques de l’intelligence artificielle et du machine learning ? Cet article démystifie les LLM, ces modèles linguistiques qui redéfinissent le traitement du langage naturel. Explorez leur architecture, leurs applications pratiques et le processus d’entraînement via des corpus textuels pour produire du contenu cohérent. Vous accéderez ici aux mécanismes clés de cette innovation, tout en prenant conscience des défis liés aux biais algorithmiques et à l’éthique des systèmes IA. Une lecture éclairante pour décoder l’impact réel de ces technologies sur notre quotidien.
Un LLM, ou grand modèle de langage (large language model en anglais), est un type d’intelligence artificielle conçu pour comprendre, générer et manipuler du texte en langage humain.
Par définition, un LLM repose sur le traitement du langage naturel (NLP), une branche de l’IA qui permet aux machines d’interpréter les mots, les phrases et le contexte.
Son fonctionnement s’appuie sur des milliards de paramètres : le modèle prédit mot après mot ce qui doit suivre dans une phrase, en s’appuyant sur d’énormes volumes de données textuelles.
Ces modèles sont aujourd’hui utilisés dans une multitude d’applications : assistants virtuels, moteurs de recherche, rédaction automatisée, traduction ou encore génération de code.
Les LLM (grands modèles de langage) reposent sur des technologies avancées comme les réseaux de neurones et l’apprentissage profond (deep learning), deux piliers du machine learning moderne.
Concrètement, le modèle est entraîné à partir de milliards de textes grâce à un processus de traitement automatique du langage. L’objectif est simple : apprendre à prédire le mot suivant dans une phrase en analysant les contextes précédents. C’est ce mécanisme qui permet ensuite la génération de texte fluide et cohérente.
Une fois le modèle de base entraîné, une phase de fine tuning permet d’adapter le LLM à des cas d’usage spécifiques (juridique, médical, support client, etc.), en affinant ses réponses selon des données ciblées.
Ces modèles d’intelligence artificielle se spécialisent dans le traitement du langage naturel (NLP), avec la capacité de comprendre, générer, traduire et résumer des textes humains. Leur rôle principal consiste à établir des bases terminologiques claires et à se distinguer des autres méthodes en traitement automatique.
Ces systèmes représentent aujourd’hui une avancée majeure dans l’apprentissage automatique, avec des caractéristiques déterminantes :
L’évolution des modèles linguistiques vers les systèmes actuels révèle une progression technologique majeure. Les premières versions s’entraînaient déjà sur des milliards de mots issus du web, mais le véritable bond en avant vient des avancées en matière de structures neuronales. Ces progrès techniques ont décuplé le nombre de paramètres, boostant leur performance en génération et analyse de texte.
Le cœur technique des LLM utilise des réseaux de neurones transformateurs, issus des avancées en machine learning, combinés à un mécanisme d’attention sophistiqué. Cette approche permet au modèle d’évaluer dynamiquement les relations entre chaque terme d’un énoncé, créant ainsi une compréhension contextuelle bien supérieure aux anciennes méthodes.
| Modèle | Architecture & Entraînement | Spécificités Techniques |
|---|---|---|
| GPT-4 | Transformer (détails non divulgués) | Accepte les images en entrée. Fine-tuning recommandé, mais performant sans. Affiné avec apprentissage par renforcement avec feedback humain. Détails techniques (taille, architecture) non spécifiés. |
| BERT | Transformer (encodeur seulement) | Base pour de nouveaux modèles avec fine-tuning ou filtrage. Nécessite souvent un fine-tuning pour les tâches spécialisées. Entraîné sur BookCorpus et Wikipedia (3,3 milliards de mots). |
| PaLM 2 | Pathways Language Model (PaLM) | Surpasse GPT-4 dans certaines tâches (mathématiques, traduction, raisonnement). Différence notable : taille des ensembles data d’entraînement. Peut coder, traduire et raisonner de manière performante. |
Légende : Ce tableau compare les architectures et les spécificités techniques de trois LLM populaires : GPT-4, BERT et PaLM 2. Il met en évidence les différences en termes de structure, de méthodes d’entraînement et de performances dans diverses applications.
La tokenisation et la gestion du contexte jouent un rôle central dans l’analyse des données textuelles. Concrètement, ces systèmes découpent le langage en unités significatives (tokens) pour faciliter leur traitement numérique. Cette étape technique détermine directement la capacité du modèle à interpréter des phrases longues ou complexes. À noter : la fenêtre contextuelle définit la quantité de texte (en tokens) que le système peut traiter simultanément.
Les LLM trouvent aujourd’hui des applications concrètes dans de nombreux secteurs, grâce à leur capacité à comprendre et produire du langage de manière fluide. Leur puissance repose sur l’interaction avec le langage et leur adaptabilité à des contextes variés. Voici quelques usages majeurs :
Les LLM deviennent ainsi des outils centraux dans les stratégies d’innovation, en simplifiant la génération, la compréhension et l’exploitation du langage à grande échelle.
L’origine des corpus d’entrainement révèle un point clé : la diversité des sources conditionne l’efficacité des systèmes. Les modèles de langage s’appuient sur des données massives issues de livres, de contenus web, d’articles d’actualité et d’échanges sur les réseaux sociaux. Cette variété nourrit leur compréhension du langage naturel.
Mais attention : le nettoyage des données textuelles représente souvent l’étape la plus exigeante. Les informations brutes comportent fréquemment des erreurs ou des incohérences qui peuvent fausser les résultats. Un prétraitement rigoureux s’impose pour optimiser les performances des modèles, surtout dans le cadre de formations spécialisées en NLP.
Les méthodes d’apprentissage auto-supervisé dominent actuellement le machine learning. Plutôt que de dépendre d’étiquettes manuelles, les modèles apprennent à prédire la prochaine séquence de texte. Cette approche générative permet de traiter des volumes colossaux de données sans supervision humaine directe.
Quant à l’optimisation technique, elle repose sur un équilibre délicat. Le réglage des hyperparamètres influence directement les ressources nécessaires – puissance de calcul, durée d’entraînement, coûts énergétiques. Signalons que les dernières avancées en matière de cloud computing facilitent désormais l’accès à ces technologies, même pour des services à moyenne échelle.
L’automatisation des processus métier apporte des gains de productivité mesurables. Ces modèles de langage trouvent leur utilité dans tous les secteurs, transformant les pratiques professionnelles – de la documentation technique à l’assistance au codage.
Les entreprises observent des améliorations significatives grâce à l’intégration de ces technologies. Voyons comment :

En pratique, ces applications transforment progressivement les méthodes de travail tout secteur confondu.
Les formations spécialisées répondent à un besoin croissant de compétences en IA générative. Pour maîtriser ces technologies en contexte professionnel, un apprentissage structuré s’impose. Ces parcours pédagogiques, souvent animés par des experts du domaine, couvrent l’ensemble des aspects techniques – du paramétrage des modèles à leur intégration opérationnelle.
Comment exploiter ces outils au maximum ? Plusieurs axes méritent attention :
Signalons que ces compétences deviennent progressivement un standard dans de nombreux domaines professionnels. Les entreprises investissent massivement dans des programmes de formation adaptés à ces nouveaux enjeux technologiques.
Un LLM (grand modèle de langage) est un algorithme spécifique de l’intelligence artificielle conçu pour le traitement du langage. Il fonctionne grâce aux réseaux neuronaux et à l’apprentissage automatique, ce qui lui permet de générer du texte en simulant une forme de capacité linguistique proche de l’intelligence humaine.
Cependant, un LLM n’est qu’un sous-ensemble de l’IA. L’intelligence artificielle englobe un champ beaucoup plus large : reconnaissance d’images, planification, robotique, prise de décision, etc. Là où un LLM se concentre sur le langage, l’IA peut traiter tout type de données.
Enfin, les deux soulèvent des questions éthiques similaires, notamment sur les biais : un LLM peut reproduire des stéréotypes présents dans ses données d’entraînement, comme n’importe quel système d’apprentissage automatique.
Comprendre l’origine des biais dans les modèles linguistiques permet de mieux cerner leurs limitations. Ces distorsions proviennent principalement des données utilisées lors de l’apprentissage des systèmes. En effet, les corpus issus du web reproduisent souvent des normes genrées ou des inégalités présentes dans la société.
Voyons les solutions concrètes pour atténuer ces effets. Le nettoyage rigoureux des données s’impose comme première étape incontournable. Prenons l’exemple des stéréotypes intergroupes : selon le contexte social évoqué, un même modèle comme ChatGPT peut produire des réponses radicalement différentes. Une étude récente en NLP montre que l’analyse fine du langage généré permet de détecter [X]% des biais implicites.
Signalons que cette problématique dépasse la simple technique. Les formations en machine learning intègrent désormais des modules sur l’éthique des LLMs. Par ailleurs, certaines plateformes utilisent des models de vérification complémentaires pour filtrer les sorties problématiques. Cette approche combinatoire représente un progrès significatif dans la génération de contenu plus neutre.
L’évolution s’oriente désormais vers des modeles multimodaux et spécialisés. Quelles perspectives cela ouvre-t-il ? Les recherches en machine learning montrent que ces systèmes pourront intégrer simultanément du texte, des images et des données audio. Cette polyphonie cognitive permet non seulement de generer du contenu multimédia, mais aussi d’enrichir les formations en ligne grâce à une compréhension contextuelle approfondie.
Voyons comment l’intégration avec l’IoT laisse entrevoir des applications concrètes. Les models de langage alimentent déjà des chatbots éducatifs et des assistants virtuels capables d’adapter leurs réponses au profil de l’apprenant. Signalons que ChatGPT et ses dérivés montrent comment le langage naturel peut servir de pont entre les données techniques et les besoins humains. Une avancée significative pour les plateformes de learning qui cherchent à personnaliser l’apprentissage à grande échelle.
L’adaptation contextuelle et le fine-tuning constituent des leviers majeurs pour améliorer les modèles après leur phase d’apprentissage initiale. La personnalisation d’un modèle de langage pour un usage métier spécifique s’appuie souvent sur cette méthode : il s’agit d’ajuster un modèle pré-entraîné à l’aide de données spécialisées, comme le détaille notre formation au Prompt Engineering pour IA générative Certifiante. Cette approche permet d’affiner considérablement les réponses générées.
Mais attention : le déploiement industriel de ces systèmes nécessite une réflexion approfondie sur l’équilibre entre consommation énergétique et puissance de traitement. Signalons que l’optimisation des performances va bien au-delà du simple ajustage technique – elle influence directement la qualité des contenus produits. En effet, un modèle bien calibré parvient à analyser le contexte avec plus de finesse, tout en maintenant une cohérence dans ses outputs. C’est précisément ce qui permet de produire des réponses pertinentes et cohérentes, notamment dans les applications de service client ou de recherche d’informations.
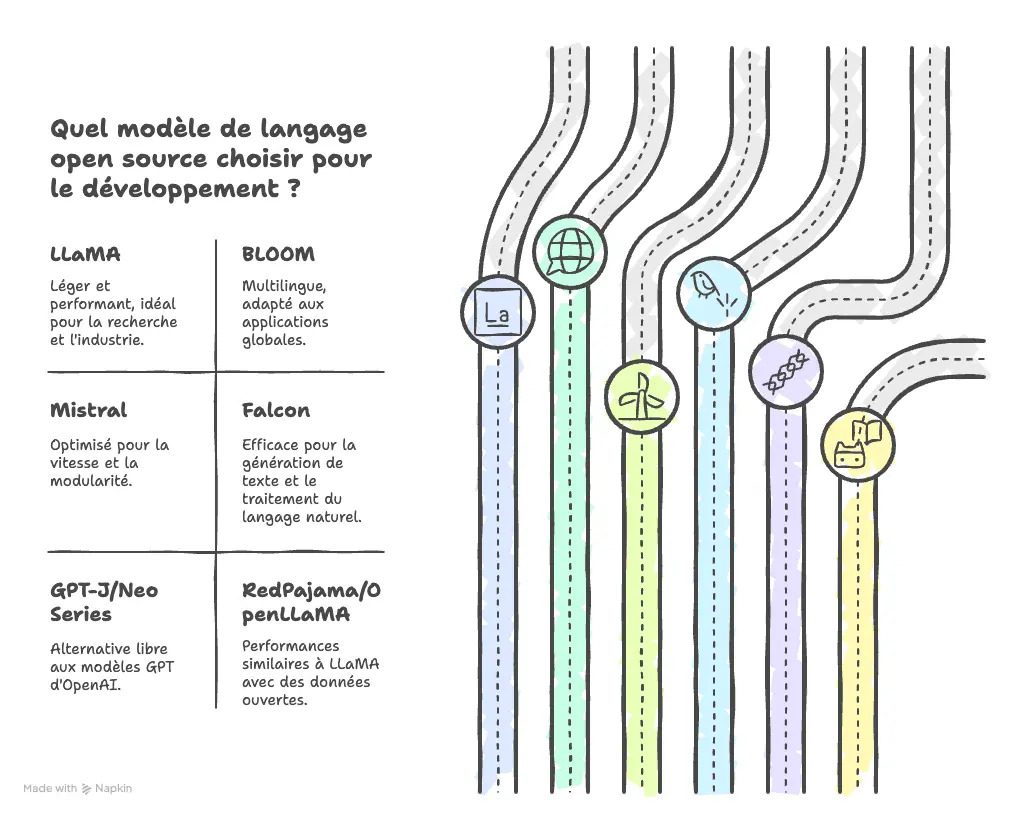
Les LLM open source (grands modèles de langage accessibles librement) gagnent du terrain face aux modèles propriétaires, portés par des initiatives communautaires et des acteurs majeurs de l’IA. Grâce à des plateformes comme Hugging Face, ces modèles sont facilement accessibles, modifiables et réutilisables pour le développement d’applications variées.
Parmi les plus connus, LLaMA (Large Language Model Meta AI) développé par Meta occupe une place centrale. Pensé pour être plus léger et performant, il se décline aujourd’hui en plusieurs versions (LLaMA 2 et bientôt LLaMA 3), très utilisés dans la recherche comme dans l’industrie.
D’autres modèles open source se sont imposés :
Ces modèles open source, en plus de rendre l’intelligence artificielle plus transparente et accessible, permettent une innovation collective, soutenue par une communauté engagée, loin des logiques fermées des géants du secteur.
La gestion des data sensibles et la conformité RGPD soulignent l’importance des enjeux réglementaires. Pour exploiter les LLMs tout en respectant la vie privée, il devient nécessaire de cartographier les processus de traitement des informations et de maintenir un registre détaillé. Cette approche offre une vision structurée des activités impliquant la collecte et l’utilisation de données personnelles.
Signalons que l’implémentation de pipelines de validation des résultats améliore significativement la qualité des sorties. L’évaluation des systèmes RAG (Retrieval-Augmented Generation) s’avère indispensable pour renforcer la fiabilité des applications basées sur les modèles de langage.
Notons que l’intégration du machine learning dans ces processus nécessite souvent une formation adaptée aux équipes techniques.
Les solutions pour limiter l’impact environnemental des modèles de langage gagnent en pertinence – et c’est là qu’interviennent des projets comme EcoLLM. Cette approche d’IA frugale vise précisément à optimiser la consommation énergétique des systèmes de génération de texte. Signalons qu’elle s’inscrit dans une réflexion plus large sur l’efficacité des architectures d’apprentissage automatique.
Singulièrement, la collaboration entre neurosciences et intelligence artificielle ouvre des voies prometteuses. Des équipes pluridisciplinaires explorent aujourd’hui comment les mécanismes du langage naturel éclairent le développement des modèles génératifs. Ces systèmes d’apprentissage automatique parviennent notamment à analyser des volumes considérables de données, dépassant parfois les capacités humaines dans certaines tâches de prédiction. Un défi subsiste : aligner cette performance technique avec une véritable compréhension contextuelle.
Les LLM, piliers de l’intelligence artificielle, transforment déjà notre rapport à la technologie. Pourquoi attendre ? Formez-vous pour maîtriser ces outils stratégiques, exploitez leur potentiel dans vos projets concrets, et participez à façonner un avenir où le langage humain devient un levier d’innovation permanente.
Pour une intégration réussie des LLM, il est crucial d’identifier les tâches spécifiques qui peuvent bénéficier de cette technologie, en évaluant les besoins de l’entreprise pour améliorer l’efficacité et réduire les coûts. Une formation adéquate des équipes est essentielle, leur permettant de comprendre les capacités et les limites des LLM, facilitant ainsi une transition en douceur.
Il est préférable d’adopter une approche progressive plutôt qu’une intégration complète immédiate, permettant aux équipes de s’adapter graduellement. La surveillance continue des performances du LLM et l’optimisation en temps réel sont également indispensables pour assurer que le modèle répond aux besoins de l’entreprise et pour résoudre rapidement les problèmes éventuels.
La surveillance continue de la performance d’un LLM en production nécessite une approche structurée, en commençant par l’observabilité en temps réel pour suivre des métriques clés comme la latence et la qualité des réponses. L’utilisation de métriques de performance telles que la précision et la perplexité est essentielle pour évaluer le comportement du modèle et détecter d’éventuelles dérives.
La détection de biais par des audits réguliers et l’analyse du sentiment et de la toxicité sont cruciales pour maintenir la fiabilité du modèle. L’évaluation humaine reste pertinente pour identifier les erreurs contextuelles que les outils automatisés pourraient manquer, assurant ainsi une surveillance complète et réactive.
La gestion des mises à jour des LLM nécessite une approche méthodique pour éviter les régressions. Des tests rigoureux doivent être effectués avant le déploiement, avec des environnements de développement et de staging distincts pour tester les nouvelles versions dans un environnement contrôlé. Un système de gestion des versions est essentiel pour suivre les différentes versions et faciliter le retour en arrière en cas de problème.
Une surveillance continue en production permet de détecter rapidement les anomalies, tandis que des mises à jour progressives, déployées initialement à un petit groupe d’utilisateurs, permettent d’identifier les problèmes à petite échelle avant un déploiement général. L’automatisation du processus de mise à jour et une documentation soignée de toutes les modifications sont également des pratiques clés.
Les coûts associés à l’entraînement des LLM peuvent être considérables, avec des dépenses significatives pour l’entraînement initial et le fine-tuning. Les coûts d’hébergement, de déploiement et de maintenance, incluant l’inférence et l’entraînement, peuvent également représenter une part importante du budget.
Pour optimiser ces coûts sans sacrifier la performance, il est conseillé d’utiliser des techniques d’optimisation de la mémoire et du calcul. L’optimisation des prompts, en utilisant l’anglais même pour générer du texte dans d’autres langues, et la compression des prompts et des réponses peuvent également réduire les coûts d’API. L’utilisation d’un LLM de référence pour entraîner un modèle plus petit par distillation est une autre stratégie efficace.
Pour garantir le respect des réglementations sectorielles telles que HIPAA ou GDPR, les entreprises doivent adopter des stratégies spécifiques. Il est crucial de sécuriser les données utilisées par les LLM, en particulier dans le secteur de la santé, en mettant en œuvre des mesures comme l’anonymisation des données, la gestion sécurisée des données et l’obtention du consentement de l’utilisateur.
L’utilisation de « data privacy vaults » peut aider à maintenir la confidentialité des patients. Il est également recommandé d’effectuer des contrôles de conformité réguliers et de suivre les bonnes pratiques pour le déploiement de LLM dans des environnements réglementés.
Les lectures qui peuvent vous intéresser :



29 juin 2026
Intelligence Artificielle – IA
29 juin 2026
Intelligence Artificielle – IA
17 juin 2026
agentsia
Laisser un commentaire